Semantics-Aware Autoencoder in Recommendation Scenarios
Introduction
Artificial Neural Networks are compelling models that can obtain a high discrimination power, but the price you pay for better accuracy is the lack of interpretability. That’s the reason why they are called black-boxes; they work, but you cannot understand how they compute the predictions. Neural Networks can approximate any function, but the study of their structure won’t give us any insight about the function being approximated, because there is no simple link between the weights and the function to approximate.
Autoencoders are widely and successfully used in collaborative filtering settings. The most common configuration consists in having input and output neurons that represent catalog’s items. This network is then trained with user ratings, and it learns how to reconstruct them by using a latent representation which is encoded in the hidden layer. Even with this simple model, its possible to outperform many state-of-the-art algorithms but the price you pay for better accuracy is the lack of interpretability.
Users, on the other hand, would like to know why a particular item has been recommended, but this may be important to users from different perspectives. For example, it can help them to better understand how the system is working and it can increase their trust in the recommender.
Idea
If it could be possible to label every neuron in hidden layers and force the neural network to be aware of the meaning of the hidden nodes, we could address the problem of deep learning models interpretability. In a recommendation scenario, if we think about an autoencoder, usually we have input and output units representing items while hidden units encode a latent representation of users’ ratings once the model has been trained. What if we find a way to replace a latent representation of user ratings with items’ attributes and force the gradient to flow only through those attributes that belong to items?
Therefore, a not fully connected architecture based on an autoencoder model comes in handy. In this model, input and output neurons that represent all the items in the catalog are connected only with those neurons that represent items’ attributes related to them.
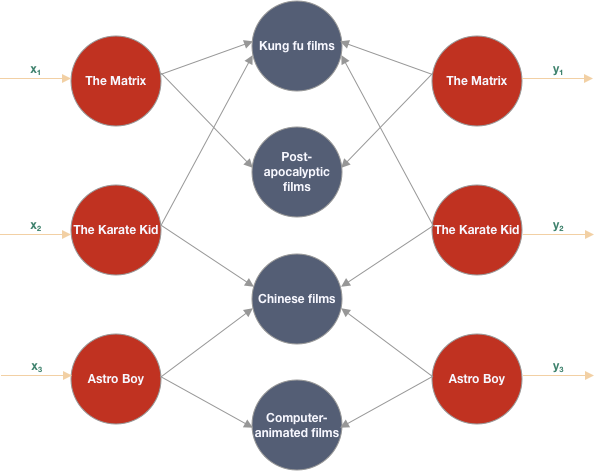
Autoencoders are capable of encoding a latent representation of their input data within the hidden layer, and they exploit it to reconstruct the original input data at the output layer. In this case, we have a not fully connected architecture that allows us to assign an explicit meaning to the hidden neurons; this means that at the end of training, a representation of the input data within the feature space is encoded in the hidden layer.
Feed Forward and Backpropagation
To train a neural network which results to be no more fully connected, it’s necessary to modify the feedforward and backpropagation algorithms because we want user ratings to propagate only through attributes that belong to rated items.
\[M_{m,n} = \begin{pmatrix} a_{1,1} & a_{1,2} & \cdots & a_{1,n} \\ % a_{2,1} & a_{2,2} & \cdots & a_{2,n} \\ \vdots & \vdots & \ddots & \vdots \\ a_{m,1} & a_{m,2} & \cdots & a_{m,n} \end{pmatrix}\]M is an adjacency matrix where rows and columns represent respectively items and features. Each entry of this matrix is a binary value that indicates whether a feature j belongs to the item i.
\[a_{i,j} \in M_{m,n} = \begin{cases} 1,& \text{if item } i \text{ is connected to feature } j\\ 0, & \text{otherwise} \end{cases}\]During the feedforward and backpropagation steps, a matrix multiplication between the weight matrices and the mask M it is needed to prevent both inputs and errors to propagate through unconnected features in the hidden layer.
Therefore it is possible to compute neurons’ value for hidden and output layers as:
\[h = g(X \times (W_1 \circ M)) \\ o = g(h \times (W_2 \circ M^T))\]New weights matrices in the backpropagation step are calculated as follows:
\[W_{1} = (W_{1} \circ M) - r \cdot \frac{\partial E}{\partial W_{1}} \\ W_{2} = (W_{2} \circ M^T) - r \cdot \frac{\partial E}{\partial W_{2}}\]User Profile
Finally, by training one autoencoder per user, it’s possible to reconstruct her user ratings starting from an explicit representation of them in the feature space instead of latent factors. Hence, the user profile can be built by extracting values encoded in the hidden layer, where each neuron corresponds to a specific feature.
Recommendations
Now that we have users’ profile, we can provide them a top-N recommendation list.
Features summation
The simplest method to predict a score for each unrated item would be a summation of features that belong to the item by using the weights in her user profile.
User-kNN
Another approach consists in leveraging a VSM model in which to project our users’ vector to find for every user, her most K similar ones to infer missing ratings by applying a user-kNN. For each user u we find the top-k similar neighbors to infer the rate r for the item i as the weighted average rate that the neighborhood gave to it:
\[r(u, i) = \frac{\sum_{j=1}^{k} sim(u, v_{j}) \cdot r(v_j, i)}{\sum_{j=1}^{k} sim(u, v_{j})}\]Explanation
Having a recommendation model which is also interpretable leads to an easy way to provide an explanation to the users. In this case, we can explain the recommended items by using the top features that give the major contribute to the ranking of that item.
References
- Semantics-Aware Autoencoder
Bellini, V., Di Noia, T., Di Sciascio, E., and Schiavone, A.
IEEE Access, vol. 7
If you publish research that uses SEMAUTO, please cite it as:
@ARTICLE{8897546,
author={V. {Bellini} and T. {Di Noia} and E. D. {Sciascio} and A. {Schiavone}},
journal={IEEE Access},
title={Semantics-Aware Autoencoder},
year={2019},
volume={7},
number={},
pages={166122-166137},
keywords={Deep learning;Recommender systems;Task analysis;Computational modeling;Engines;Companies;Tools;Autoencoder neural network;cold start problem;deep learning;explanation;knowledge graph;recommender system},
doi={10.1109/ACCESS.2019.2953308},
ISSN={2169-3536},
month={},}